What You Should Know About Disaster Recovery

Shit Happens All The Time
Recent news reminded a lot of people that a disaster can occur in any datacenter: 3.6 million websites went down after a fire blew up a datacenter of the french hosting company OVH. Octave Klaba, the CEO of OVH, quickly asked his customers to execute their disaster recovery plans.
🔥 Incendie sur le site d'OVH Cloud à #Strasbourg : une centaine de #Pompiers67 🚒 a été mobilisée cette nuit dont le bateau-pompe franco-allemand Europa1. Les actions menées ont permis de préserver la majeure partie des bâtiments de l'entreprise. COD activé. Pas de blessé. pic.twitter.com/RKjI6F9DB7
— SDIS du Bas-Rhin (@sdis67) March 10, 2021
It’s not my job to design, build and manage data centers, so I won’t lecture OVH here (and not only because Octave and I attended the same university). The rule is the same for everyone: sometimes, something will break and you have to prepare for it.
So let’s take this event as an opportunity to learn new things and explain how we can prepare for this. I will also explain how and in what measure, we are prepared for such an event at Nuxeo.
High Availability
The first thing you usually plan is to have a cluster of servers: if one server fails, then the other can handle the requests. It usually works well if both servers are placed not too far and have low latency with the load balancer. This is the case for instance in AWS when you place your servers in different availability zones. Availability zones are not supposed to fall at the same time and are supposed to have a separate source of power and network.
In the case of the OVH disaster though, it seems that the 4 data centers located in Strasbourg shared some infrastructure. For safety reasons, they also cut the power on all datacenters when the firemen were trying to extinguish the fire. So in that case, even if you have spread your server across DCs, they are still all shutdown. That also means that you have to know the location of your servers so that you can plan for this.
At Nuxeo, we run our servers on AWS and the Nuxeo clusters are spread across several AZs. As we use an autoscaling group, if an AZ is falling then the ASG is supposed to schedule a new EC2 instance in another AZ. Moreover, the asynchronous works are backed by Kafka that is also deployed on several AZs which gives us strong HA capabilities: if a work like an indexation or the computation of a thumbnail does not finish on a node, it will be rescheduled by Kafka on another node.
As always, it’s good to plan for high availability but you only know if it works by testing it. This is done by using chaos engineering, by removing parts of the infrastructure, for instance: a node, a network, a firewall rule, or slowing things down. Running in a fully managed cloud infrastructure where you can manipulate those objects with an API helps here.
Backup And Restore
Then, of course, the thing that comes to mind when running an application is to plan for backup and restores. This may look easy, but in various scenarios, you have several sources of data to back up and all data have to stay consistent. In a Nuxeo application for instance you have the Database and the Index which are the source of data. If you backup both sources at a different time, then restoring them will end up in an inconsistent state: some data may have been indexed but not present in the DB backup for instance.
Some data can also be rebuilt. For instance, the Nuxeo repository can be reindexed to rebuild the index data that don’t need to be backup. This comes with a drawback though: indexing takes time.
This may seem obvious, but the backups have to be sent to another region, otherwise, if the site is lost, then your backups are lost too! In AWS, S3 offers cross-region replication of the objects. Simply enabling this option on the bucket where you save your backups will get you in a safe spot. At OVH, that’s what is called backup storage, and 500GB of storage is offered for free for every dedicated server.
At Nuxeo, the MongoDB repositories run a continuous backup strategy with snapshots taken every 6 hours. That means that the MongoDB oplog is replicated continuously, allowing for point-in-time recovery, and a snapshot of the DB is taken every 6 hours. Those snapshots are then sent to an S3 bucket with cross-region replication configured. We run a full reindex after the restore. The time it takes is then depending on the size of the repository. As we store our binaries in S3, we use S3 cross-region replication to replicate the blob of the documents in real-time in another bucket, in another region. In Nuxeo Cloud, your data are safe.
RTO And RPO
Recovery Time Objective (RTO), and Recovery Point Objective (RPO) are the two metrics that are measured in a DR scenario:
- RTO: this is the time needed to get the service back, once the decision to activate the DR plan has been taken. With a single restore, this is usually the time to reinstall the infrastructure somewhere else and run the restore.
- RPO: this is the maximum amount of data that you may have lost during a disaster. This is usually the period between your backups.
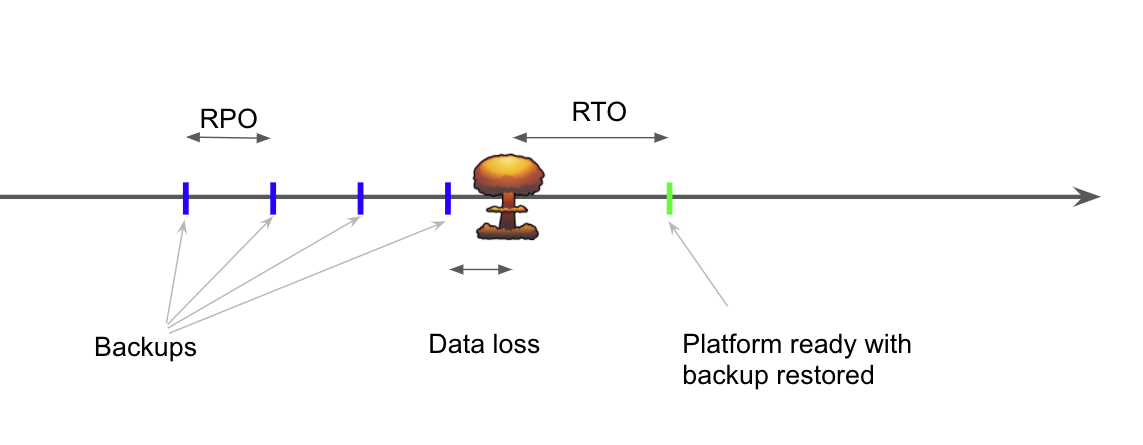
The idea is to try to lower as much as possible those two metrics. To lower the RTO, the idea is to plan the DR procedure and automate everything so that when it’s needed, it’s just a matter of minutes to execute. The restore time depends on the size of the data that you are restoring. If you need to lower that time, you may want to shard your data to have several smaller databases that are quicker to restore in parallel. Again, in this situation, there is no place for manual restore: everything must be automated.
To lower the RPO, the idea is to do more frequent backups with a combination of full and incremental backups.
At Nuxeo, the installation of a complete environment takes less than 15 minutes to complete and is completely automated. Once the process is completed we can run our DR automation to restore the data.
This Is Not Enough
In a backup/restore DR plan, the RTO/RPO is often in the magnitude of a couple of hours. In critical situations, you cannot afford this and you need to be back up in a few minutes. To do that, there are different possibilities:
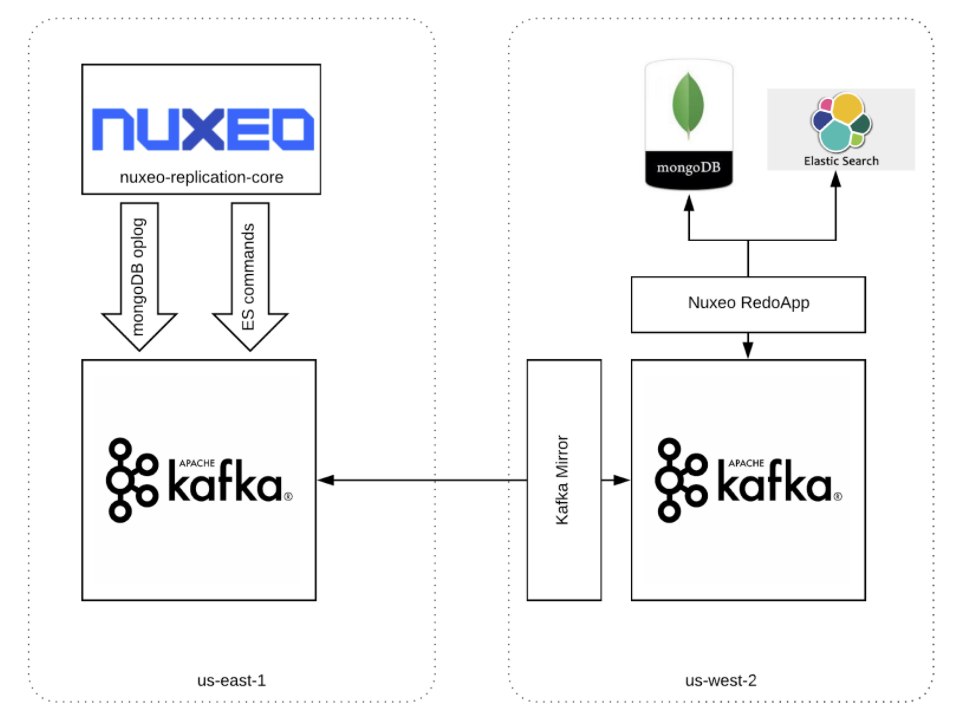
- Active / Passive replication: there is an active application in region A and a passive instance in region B. Usually, the passive instance is not started and only the DB are up. A mechanism then streams the change of data from region A to region B and those changes are replicated onto the DB of region B. In the case of disaster, we just need to start the application on region B and switch the DNS route. Most databases provide that kind of replications. At Nuxeo, we developed a streaming replication mechanism that allows streaming the changes from the DB, the index, the work, and the binaries to a distant region at the same time and in a consistent manner. This is not part of the cloud offering yet.
- Active / Active replication: in that kind of setup, we have two active regions that are kept in sync. If a region fails, then the other can serve the requests of the two regions. This is very complex to achieve as some coherence problems usually arise between the two regions. In AWS, DynamoDB offers natively some streaming replication that allows executing that kind of active/active replication. In that particular scenario, you also have to size each environment being capable of handling the load of the two environments. If one node fails, all the load will be to the first one. If you did not plan for that, the result may be catastrophic.
Of course, having a secondary active or passive site brings additional costs but also some additional complexity and maintenance. For instance, in the first scenario, you have to ensure that the replication process is constantly working and doesn’t lag too much, or your RPO will increase accordingly. That additional maintenance adds to the price of having 2 environments running at the same time.
Rehearsal
It’s great to plan for DR, but if planning is a nice idea, you need to verify that your plan is working well. That means that you need to rehearse your plan regularly, not just once. In a few months, a lot of things can change: the tooling evolves, the libraries that you rely on can change, some of them may not work anymore, etc… You don’t want to fix some library compatibility issue the day you need to run it for real.
At Nuxeo, we run DR drills twice a year to be sure that our automation can still run them. One of the scenario we also would like to test is if the disaster happens on a site where our automation executer is running. Basically, you want to be able to re-install this platform on another site and run the DR scenario from there (and yes the installation of our automation platform is also completely automated).
Conclusion
To sum up:
Everything fails all the time, Werner Vogels
and that means everything, even the datacenters. OVH ran into a big industrial disaster this week and I’m sure Octave Klaba will make everything to learn from that event. Yes, the blast radius was too big and not limited to only one DC, yes using water was probably not the best technical solution to protect servers from fire… but it happened. OVH has some responsibility and they are accountable for it, but they are not 100% responsible for the 3.6 million sites down.
As developers, as ops, we are also responsible to put in place all the DR processes and the infrastructure that needs to mitigate that kind of event. I often refer to a very interesting talk by Neal Ford that I attended called “Abstraction Distractions”. When developing the last streaming solution capable of handling millions of events per second, we can quickly forget that this all runs in datacenters with electricity. Some people were reminded of that this week: nobody can guarantee that their data center is 100% safe.
Depending on your activity, targetting an RTO/RPO in the design phase of a solution will help you choose what kind of backup you need. The SLA that you are targetting is a good indicator of the type of DR solution that you want. But it is also a good indicator of the price that you’ll have to pay. Usually, adding one nine will increase your yearly bill a lot, but not doing it can cost you a lot too!
References
- Millions of websites offline after fire at French cloud services firm
- Abstraction Distraction by Neal Ford
- High Availability on Wikipedia